Interaktiv Benchmarking
IB®
Brugermanual og Hjælpeskærme
Ver. 2.8
September, 2012
Peter Bogetoft
Bemærk: Nogle af
faciliteterne, som er beskrevet i denne manual, er muligvis ikke tilgængelige
for dig. De tilgængelige faciliteter afhænger nemlig af dit abonnement.
Derudover er nogle af faciliteterne (såsom Spørgeskema) kun tilgængelige i den
web-baserede version. Hvis du er interesseret i at udvide de faciliteter du har
adgang til kan du henvende dig til contact@ibensoft.com.
Indhold
Generel information om Interaktiv Benchmarking IB(R)
Login
Model:Prædefineret Model
Model: Selvdefineret Model
Enheder: Min Enhed
Enhed/Virksomhed: Fusion
Enhed/Virksomhed: Potentielle Peers/Forbilleder
Scenarie/Spørgeskema
Nøgletal-KPI
Benchmark
Peers / Forbilleder
Sektor Analyse
Dynamisk
Rapporter
Data
Generel information
om Interaktiv Benchmarking IB®
Ideen
Interaktiv
Benchmarking er et interaktivt computerprogram, der organiserer og analyserer virksomheders
data med henblik på at forbedre performance.
Programmet
kombinerer state-of-the-art benchmark teori, beslutningsstøtte metoder og
computer software med det formål at identificere gode rollemodeller og brugbare
præstationsmål.
Baggrund
I de seneste
årtier har teoretikere og praktikere arbejdet meget med benchmarking og relativ
præstationsvurderinger, og der er sket store fremskridt. Selv de bedste
analyser vil imidlertid være baseret på en række antagelser. Da enheder eller
virksomheder som analyseres kan derfor sætte spørgsmålstegn ved disse antagelser
og dermed også ved relevansen af de opnåede resultater. Brugeren af en analyse
vil desuden typisk stille en række ”hvad nu hvis” spørgsmål. Dette skaber et
behov for fleksible benchmark redskaber så analyserne kan tilpasses den
specifikke kontekst og den specifikke bruger.
Skræddersyet
benchmarking
For at skræddersy
de enkelte benchmarks har vi integreret state-of-the-art metoder i et let
anvendeligt software. Interactive Benchmarking IB® er en
analyseramme som kan erstatte en benchmark rapport baseret på en analytikers mere
eller mindre velbegrundede antagelser. En Bruger interagerer direkte med et
computer program IB for at få analyserne til at afspejle Brugerens specifikke
fokus, kontekst, mission og ambitionsniveau.
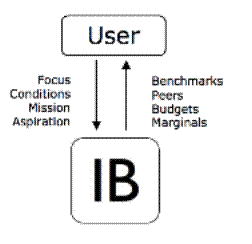
Fokus: Brugeren vælger et fokus (Model) for analysen. Fokus kan være kortsigtet
eller langsigtet, og det kan involvere hele virksomheden eller dele af den.
Benchmarksystemet indeholder på forhånd nogle relevante modeller, men det giver
også Brugeren mulighed for at udvikle alternative modeller, som bedre afspejler
Brugerens fokus.
Betingelser: Modellerne er konstrueret, så de så vidt muligt
afspejler rammebetingelserne. Brugeren kan dog vælge at lave yderligere
antagelser om den evaluerede enhed (MinEnhed) og den relevante
sammenligningsgruppe (Potentielle Peers). Den evaluerede Enhed kan være en
realiseret enhed, en budgetteret enhed, en fusioneret enhed etc. Tilsvarende
kan sammenligning med nogle af de andre virksomheder ekskluderes vha. filtre på
de tilladte Potentielle Peers. Brugeren kan for eksempel være interesseret i
kun at sammenligne med lokale selskaber fra samme branche og med nogenlunde
samme størrelse.
Mission: Brugerens specifikke mission eller strategi kan specificeres
yderligere ved at definere søgeretninger. Det kan således specificeres hvor opsat Brugeren
er på at reducere de forskellige inputs (ressourcer) og på at øge de
forskellige outputs (produkter og serviceydelser)?
Aspiration: Aspirationsniveauet i forholde til andre kan også justeres.
Selvom ”bedste praksis” typisk har mest interesse kan Brugeren også vælge at gå
efter mindre ambitiøse mål, fx 25% under bedste praksis. Tilsvarende kan Brugeren
også være interesseret i hvor godt andre virksomheder gør det i forhold til den
samme mission. Brugeren kan til det formål analysere alle selskaber i
industrien ud fra de forudsætninger, han anvender om den evaluerede Enhed.
Andre generelle træk ved IB
Let at bruge: Styringen af benchmarkprocessen
foregår ved hjælp af forskellige kontroller, menuer og valgmuligheder, som er
både simple og intuitive at anvende. Derudover er der et omfattende tekst- og
video-baseret hjælpesystem, hvis Brugeren skulle komme i tvivl om muligheder og
fortolkninger.
Direkte anvendelige: Resultaterne er direkte anvendelige ifm konkrete
organisatoriske og forretningsmæssige beslutninger. De spørgsmål, som IB kan
svare på, og den måde resultaterne vises, er udviklet i et nært samspil med
konkrete virksomheder og brancheorganisationer mv. IB beregner planer og
budgetter, og IB identificerer peers man kan lære af i implementeringsfasen. IB
gør det let at udregne marginalomkostninger, substitution mellem
produktionsfaktorer, samt trade-off mellem serviceydelser. IB tillader også brugeren
at forudsige synergien ifm fusioner og andre samarbejder, at vurdere selskabers
stordriftsmuligheder etc etc.
IB er desuden
ikke bare et måleredskab men også et læringsmiljø, hvor brugeren kan lære
virksomheden at kende og undersøge muligheder og begrænsninger. Den bagved
liggende model bygger på komplekse, praksisbaserede sammenhænge mellem mange
inputs og outputs.
Forskningsteam: Bag den simple og intuitive brugerflade er IB et
program, der kombinerer bedste praksis i præstationsevaluering og computer
teknologi. Det er udvikles af et team, som ledes af professor Peter Bogetoft.
Peter Bogetoft er en førende international forsker inden for performance
evaluering, forfatter til mere end 50 peer-reviewed artikler og bøger, samt konsulent
på talrige benchmark opgaver i hele verden.
Tekniske detaljer: For mere information om teorien, samt de matematiske
og statistiske metoder bag, kontakt udviklerne af programmet på contact@ibensoft.com
Login
Login
Login kræver et brugernavn og password. Brugerens rettigheder og muligheder
afhænger af brugertypen. Brugens login bestemmer således, hvilke faneblade der
kan ses og hvilke faciliteter der er tilgængelige i de forskellige faneblade.
”?”
I det øverste
højre hjørne af skærmen linker ”?” videre
til hjælpesystemet. De forskellige hjælpeemner er specifikt relateret til det
faneblad du arbejder på, når du aktiverer hjælpen, men du an naturligvis bevæge
dig rundt i hele hjælpesystemet derfra.

I øverste højre
hjørne linker filmsymbolet til små videoer, der forklarer hvad man kan i det
faneblad, som er aktivt når filmen kaldes.
Den typisk IB session
Ved normal brug
af IB starter man med fanebladet længst til venstre på skærmen og arbejder sig mod
højre.
-
Du
kan hele tiden gå tilbage til et tidligere faneblad og ændre dit valg. Du kan
for eksempel ændre modellen, der bliver brugt, eller ændre den enhed, der
bliver analyseret.
-
I en
session vil fanebladene lyse op efterhånden som de bliver tilgængelige. Du kan
for eksempel IKKE bruge Benchmark før du har valgt en model og en enhed, som
skal analyseres.
-
Analyserne
i et givet faneblad afhænger af de valg som er foretaget i tidligere faneblade.
Hvis du hopper tilbage, dvs. til venstre i fanebaldene vil alle valg foretaget
i faneblade til højre for det du nu står i, som hovedregel være annulleret.
Generelle IB
kontroller
Der er mange
muligheder for at ændre udseendet af de forskellige vinduer. Mulighederne og
knapperne er intuitive og baseret på standarderne i Windows. Træk rækker,
kolonner og vinduer rundt som du har lyst i IB-Win.
Der er tilsvarende
omend færre muligheder i den web-basered udgave IB-Web.
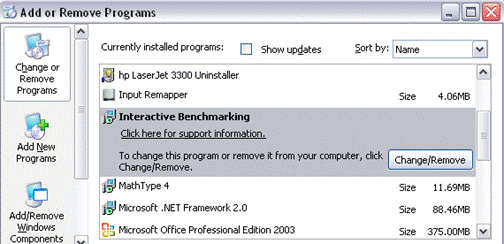
Sådan opdateres
IB-Win
-
Hver
gang du starter en session tjekker IB om du har Internet adgang. Hvis dette er
tilfældet vil programmet automatisk lede efter opdateringer.
-
Hvis
en opdatering findes kan du vælge at installere den.
-
Hvis
du senere fortryder opdateringen kan du vælge at gå tilbage til en tidligere
version af programmet ved at bruge ”Tilføj og Fjern Programmer” i Windows
kontrolpanel.
Sådan opdateres
IB-Web
IB-Web opdateres
løbende efterhånden som nye muligheder udvikles og afhængigt af de
brugerrettigheder den aktuelle Bruger er udstyret med.
Model: Prædefineret
Model: Prædefineret
-
Du
kan se de prædefinerede modeller i under-fanebladet Model: Prædefineret.
-
Når
du markerer en Prædefineret model vises en kort beskrivelse af modellen
-
De
foruddefinerede modeller giver brugeren et udgangspunkt for sine analyser.
Brugeren kan definere alternative modeller under fanebladet Model: Selvdefineret.
Modellen
En model er
defineret vha. inputs, outputs og situationsvariable.
-
Inputs repræsenterer udnyttede ressourcer, omkostninger
etc.
-
Outputs repræsenterer de produkter og serviceydelser der
produceres
-
Situationsvariable er tilstande virksomheden ikke kan
kontrollere, men som kan lette eller besværliggøre transformationen af inputs
til outputs.
En model
definerer ens fokus for analysen. Den kan være kort- eller langsigtet, og den
kan involvere hele virksomheden eller dele af den; for eksempel en proces.
Model: Selvdefineret
Model: Selvdefineret
I under-fanebladet
Model: Selvdefineret kan du definere din egen model ved at specificere
-
Inputs (I), dvs. brugte ressourcer og omkostninger
-
Outputs (O), dvs. producerede produkter og serviceydelser
Du kan vælge
imellem alle variablene, der til at begynde med er markeret som
-
Øvrige (R), dvs. variable der enten kan bruges i modellen
eller bruges til at forstå resultaterne på et senere tidspunkt (read-only).
Datasættets størrelse
Når inputs og
outputs vælges, beregner programmet den relevante (del-) mængde af selskaber,
som man kan regne på, dvs de enheder, som der er tilstrækkelige oplysninger om for
alle valgte variable.
Låste variable
Tabellen giver også en
række
-
Låste variable (L). Disse variable kan ikke anvendes som
inputs eller outputs, idet de indeholder ikke-numerisk information.
Brug af andre
variable
Øvrige (R)
variable der ikke bliver brugt direkte som Inputs eller Outputs, samt
Låste (L) variable (hvis det giver mening) kan bruges til at bestemme relevante
sammenligningsvirksomheder under fanebladet Enheder: Potentielle Peers.
De kan også bruges som mulige forklarende variable for performance i Sektor:
Vis grafer: Efteranalyse.
Estimeringsmetode
Modelspecifikationen
(Inputs og Outputs) definerer fokus for modellen. For at der er tale om en
rigtig model skal vi også bestemme sammenhængen mellem de forskellige variable.
Estimeringsmetoden brugt i de selvdefinerede modeller bruger såkaldt minimal ekstrapolation.
Ideen med de tilsvarende ikke-parametriske FDH og DEA procedurer er at
ekstrapolere mindst muligt fra data –at finde den tættest mulige approksimation
af det virkelige data.
Det er også muligt at bruge modeller, som er
estimeret vha. parametriske (PAR) økonometritilgange som fx SFA. Disse estimationer
skal foregå før analyserne starter og de resulterende modeller skal defineres i
datasættet. PAR er derfor ikke en valgmulighed i fanebladet Model:
Selvdefineret, men kan findes under fanebladet Model: Prædefineret.
Skalaafkast
I en
selvdefineret model skal du også specificere skalaafkastet, dvs dine forventninger
til effekterne af at øge eller mindske skalaen af produktionen. Spørgsmålet er
om det kræver flere inputs pr. output, når virksomheden bliver større (stordriftsulemper)
eller mindre (smådriftsulemper). Hvis
vi øger mængden af inputs med en vis procentdel, men vi ikke mener at outputs
vil blive øget med samme procentdel, da tror vi der er en ulempe ved at være
stor. Tilsvarende, hvis vi mindsker mængden af inputs med en bestemt faktor og
tror at outputs vil falde med en større procentdel, da tror vi, at der er
ulemper ved at være lille. En typisk grund til at forvente problemer med en for
stor virksomhed vil bl.a. være en stigning i koordinations- og
kommunikationsopgaver. En typisk
grund til at forvente problemer med en for lille virksomhed vil være de faste
omkostninger eller et behov for mere effektiv specialisering.
Mulige skalaafkast
Der er seks
mulige indstillinger for skalaafkastet:
- Konstant skalaafkast (CRS) betyder, at vi ikke tror der vil være ulemper ved at være
hverken stor eller lille.
- Aftagende skalaafkast (DRS) betyder at der kan være ulemper ved at være stor, men
ikke ved at være lille.
- Voksende skalaafkast (IRS) betyder at der kan være ulemper ved at være lille, men
ikke ved at være for stor.
- Variabel skalaafkast (VRS) betyder at der kan være ulemper ved at være for lille og
ved at være for stor.
- Udvidet Fri Bortkastelse (FDH+) bliver brugt sammen L og H værdier, hvis vi ikke tror
der er generelle skalaegenskaber men dog mulighed for en lokal reskalering
uden at løbe ind i problemer.
- Additivitet (ADD) betyder at man altid kan gentage hvad andre har gjort,
og man kan derfor også lave enhver form for (heltalling) kombination af
hvad andre har gjort.
Hvis du senere
fortryder dine første antagelser om skalaafkastet, kan du altid ændre disse i fanebladet
Benchmark, se nedenfor.
Navngiv modellen
- Før du kan fortsætte, bliver du også nødt til at navngive modellen og komme med en kort beskrivelse.
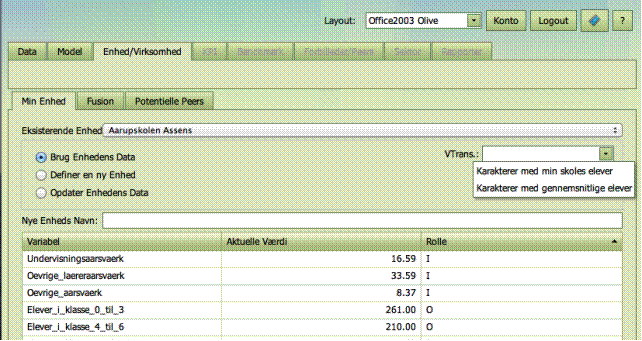
Enheder: Min Enhed
I Min Enhed kan
du vælge den enhed du ønsker at analysere.
Eksisterende Enhed
- Du kan vælge at analysere en Eksisterende enhed
- Enhedens værdier for Inputs (I) og Output (O)
blive vist i tabellen
Selvdefineret Enhed
- Du kan også vælge at definere din egen enhed,
Ny Enhed
- Du kan da selv navngive enheden
- Du skal i dette tilfælde selv indsætte de
relevante værdier for Inputs og Outputs i tabellen.
- Hvis din Selvdefinerede Enhed ligner en som
allerede eksisterer kan du blot markere den eksisterende enhed og ændre i
dennes tal indtil de passer med det du ønsker.
Brugen af en
Selvdefineret enhed
I mange tilfælde
kan det være nyttigt at definere din egen enhed. Dden nye enhed kan fx
repræsentere din enhed forbedringer…
- … af et eksisterende budget
- … i et gennemsnitligt år
- … efter allerede planlagte ændringer
Brugen of variabel
transformationer (ændringer)
I nogle anvendelser
er det nyttigt tillade forskellige versioner af inputs og outputs. I en skolebenchmark
kan vi for eksempel være interesseret i at genberegne performance for alle
skolerne, hvis de alle havde elever med samme socioøkonomiske baggrund, som den
skole vi er ved at undersøge. Tilsvarende kan vi også være interesserede i
virksomhedernes performance i forskellige økonomiske scenarier med fx stigende
og faldende renter. De nødvendige genberegninger af de forskellige datapunkter
kan gøres ved at bruge variabel transformation Vtrans i fanebladet Min Enhed. Vtrans-funktionen er tilgængelig,
når sådanne transformationer er defineret i et Vtrans regneark i det relevante
Data xls ark.
Enheder:
Fusion
I Fusion kan du
analysere performance (resultater) for en potentiel fusion af to eller flere
enheder.
Metode
Først markerer du hvilke
eksisterende enheder du ønsker at inkludere i den potentielle fusion.
Interaktiv Benchmarking IB® navngiver dernæst den nye enhed som
”Kandidat1+Kandidat2+…+KandidatK”
samt beregner
enhedernes kombinerede ressourceforbrug (summen af deres inputs) som inputs og
deres kombinerede produktion (summen af deres outputs).

Denne enhed kan
nu analyseres som enhver anden Selvdefineret enhed. Et højt sparepotentiale
sammenlignet med de individuelle enheder i fusionen indikerer, at der er et
store synergieffekter. Mere avancerede dekomponeringer af disse gevinster er
også mulige i Benchmark fanebladet.
Advarsler
I nogle modeller
vil den simple sammenlægning af inputs og outputs som ikke give mening. Et
eksempel på dette kan være, når nogle inputs eller outputs repræsenterer andele
(ratioer) eller delmængder, fx den procentdel af produktionen som har hæj
kvalitet. I sådanne tilfælde bliver man enten nødt til at omdefinere
produkterne til enheder der kan adderes; fx opdeling af output med høj og lav
kvalitet. Eller man kan beregne det endelige resultat af den fusionerede enhed
ved at vægte de enkelte enheders fysiske produktioner, addere dem og derefter
bruge de resulterende værdier til at definere en ny enhed i fanebladet Enheder:
Min Enhed.
Fortolkning
I den beregnede fusionerede
enhed vil de kombinerede input- og output- værdier svare til, at enheden
opererer fuldstændig decentraliseret; hver af de oprindelige enheder kunne køre
videre som uafhængige divisioner under et fælles navn.
De mulige
forbedringer i den fusionerede enhed
”De muliged
forbedringer af den fusionerede enhed ”Kandidat1+Kandidat2+ … +KandidatK” kan
derfor ses som forbedringer der opstår ved indlæring af ”bedske praksis” og ved
en optimal udnyttelse af de mulige synergi effekter mellem de indbefattede
enheder. Sidstnævnte effekt kan ydermere opdeles i en mix og en skala
komponent. En formel opdeling af disse effekter og organisatoriske fortolkninger
blev udviklet af Bogetoft, P. og Wang, D., Estimating the Potential Gains from
Mergers, Journal of Productivity Analysis, 23, pp. 145-171, 2005, og dekomponeringen
er iørvigt implementeret i Fusions Analyse pop-up faciliteten in the Benchmark
fanebladet.
Horisontale eller
vertikale fusioner
Fusionsmuligheden
i Interaktiv Benchmarking IB® kan direkte bruges på horisontale fusioner, dvs.
integration af enheder som producerer den samme slags serviceydelser (outputs)
og bruger den samme slags ressourcer (inputs).
En vertikal
fusion er, når en upstream virksomhed integreres med en downstream virksomhed.
Upstream-virksomheden producerer serviceydelser (komponenter), der bliver brugt
som ressourcer i downstream-virksomheden. Man kan også evaluere vertikale fusioner
med Interaktiv Benchmarking IB®. For at gøre dette bliver man nødt til at
modellere begge produktionsprocesser, som en speciel form for kombineret model.
Det kan lade sig gøre ved at ”tænke” i netputs (net outputs), dvs. ved at se
inputs som negative netputs og outputs som positive netputs. Denne strategi kan
også bruges til mere avancerede konstellationer, hvor nogle af
upstream-virksomhedens outputs er færdige produkter mens andre stadig er
komponenter, der bliver brugt som inputs i downstream-virksomheden. For mere
information om vertikale fusioner og netværker se
Bogetoft, P.,
Efficiency Gains from Mergers in the Health Care Sector, Part B: Modelling and
Part C: Implementation, Research Papers 2008:07 and 2008:08, NZa, The
Netherlands.
Enheder: Potentielle
Peers
I Potentielle
Peers kan du bestemme hvilke enheder du ønsker at sammenligne Min Enhed med.
Vær Opmærksom
Benchmarkmetoden
vil typisk selv finde rimelige Peers ved at lede efter en kombination af
enheder, som minder om den analyserede enhed på de centrale variable, inputs og
outputs. De af programmet bestemte Peers er også en god indikator for om
modellen er specificeret nogenlunde korrekt.
Peers vindue
- Det højre Peers-vindue viser de potentielle enheder, der er tilbage, som
kan bruges til at lave sammenligningen.
- De individuelle enheder kan ekskluderes ved
afmarkere dem – og du kan tilsvarende fortryde dine valg ved at markere
dem igen. Udvælgelsen kan også laves i fanebladet Benchmark.
Filtre
- Til at specificere den relevante sammenligningsgruppe
kan du også vælge at bruge Filtre.
De er defineret øverst til venstre i fanebladet Potentielle Peers.
- Du kan definere et filter ved at bruge
logiske udtryk.
- Ved at trykke på + genereres et nyt filter. Valgmulighederne til hver position
kommer frem ved at flytte musen henover linjen.
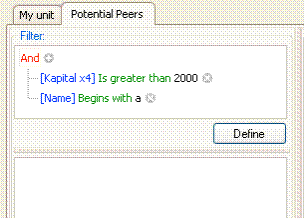
- I eksemplet nedenfor er vi kun interesseret i
at sammenligne med enheder, som har ”Kapital” på mindst 2000 og et navn,
der starter med a.
- Ved at trykke på Anvend Filter aktiveres de valgte filtre.
Potentielle peers og
Inkluderede
- Potentielle peers angiver størrelsen på
sammenligningsbasen. Det kommer an på den valgte model om der er de
tilstrækkelige data til, at et selskab kan bruges til sammenligningen.
- Inkluderede angiver antallet af Potentielle Peers
minus de individuelt til- eller fravalgte enheder. Enheder kan fravælges
enten ved direkte ved at fjerne deres markering, ved filtre eller ved at
fravælge dem i Benchmark fanebladet.
Grupper
Interessante
Potentielle Peer Grupper, der er defineret vha. filtre eller individuelle til-
og fravalg af enheder i listen af virksomheder i højre side, kan gemmes som
Peer Grupper ved at trykke på knappen Gem
Gruppe.

De kan da blive
navngivet af brugeren eller allerede være defineret og navngivet på forhånd af
dataudbyderen.
Grupperne er
nyttige i analysen, idet brugeren kan være interesseret i at begrænse
sammenligningsgrupperne.
Lager af filtre i
IB-Win
- Nederst i det venstre vindue kan du finde
lageret af filtre du har defineret.
- De aktive filtre er krydset af i listen. De deaktiveres
ved at afmarkere dem og (re)aktiveres igen ved at markere dem.
- Deaktiver alle gør dette lettere, hvis mange filtre
er blevet kombineret.

Rediger og Fjern
- Et eksisterende filter kan redigeres. Tryk Rediger og det valgte filter
flyttes til definitionsvinduet, hvor det kan justeres.
- Et filter kan også slettet ved at bruge Fjern/slet knappen.
Brug af filtre og
Udvælgelse
I mange
situationer er det nyttigt at kunne lave specifikke restriktioner på de
analyserede enheder. Af klassiske eksempler kan bl.a. nævnes
- Nominale variable – fx andelsselskaber eller
investor-ejede selskaber, liberale eller konservative regioner, øst eller
vest etc. Sådanne variable kan anvendes til at lave mere interessante
sammenligninger, hvis man deler data op. Et andelsselskab kan for eksempel
være mere interessant i sammenligninger med andre andelsselskaber end med
investor-ejede selskaber.
- Ordinale variable – fx lav, mellem og høj kvalitet,
komplicerede eller simple tilfælde etc. Sådanne variable kan ligeledes bruges
til opdeling af selskaberne. Man kan fx sige, at simple produkter af lav
kvalitet produceret under nemme vilkår og kan benchmarkes mod lignende
eller mere komplicerede produkter af højere kvalitet, som er produceret
under svære vilkår. Det kan derimod dårligt give mening af sammenligne de
sidste med de første.
- Tidsvariable – fx data fra forskellige år – kan
også være interessante at bruge som en filter parameter. Fx til at
evaluere fremgang sammenlignet med sidste års ”best practice”.
Scenarie/Spørgeskema
IB-WEB bruges ikke
kun til at lave benchmark på allerede eksisterende data, men kan også bruges
til at indsamle, validere, og benchmarke nye data.
Programmet kan
også bruges til at opsætte alternative scenarier og dermed alternative
versioner af Min Enhed, der kan blive benchmarked som en del af en
planlægningsopgave. I stedet for at introducere nye værdier af de forskellige
variable i en ny selvdefineret enhed, kan man bruge Scenarie programmet til at
beregne og definere nogle af (eller alle) de forskellige variable i modellen.
Valgmulighederne
inden for Scenarie/Spørgeskema er bestemt af den valgte model, dvs. forskellige
Scenarie/Spørgeskema skabeloner kan være knyttet til forskellige modeller. Når
man bruger Scenarie programmet kan det være en god ide at starte med en
eksisterende enhed, idet værdier som ikke specificeres i det valgte scenarie da
automatisk vil blive taget fra enhedens oprindelige værdier.
Som bruger kan du
vælge selv at
- Angive værdierne i enhver celle i
Scenarie/Spørgeskema
- Beholde standardværdierne som findes i
spørgeskemaet, hvis de er passende for din analyse
Når du har
udfyldt spørgeskemaet kan du
- Opdatere spørgeskemaet. Dette vil få IB til at
beregne alle afledte værdier (resultater) vist til højre for
svar-cellerne, såvel som alle valideringsadvarsler vist/angivet med rød
til højre for de udledte værdier (resultater).
- Gemme informationen så den kan bruges i den
nuværende og senere IB sessioner. Her bliver du nødt til at indikere,
hvilken Enhed du har angivet information for/til. Du kan også introducere
et nyt navn til enheden her.
- Sende information til spørgeskema
leverandøren.
Nedenfor er vist
et eksempel. Her gemmer vi en version af Center 1, hvor omkostningsfordelingen
er blevet ændret.
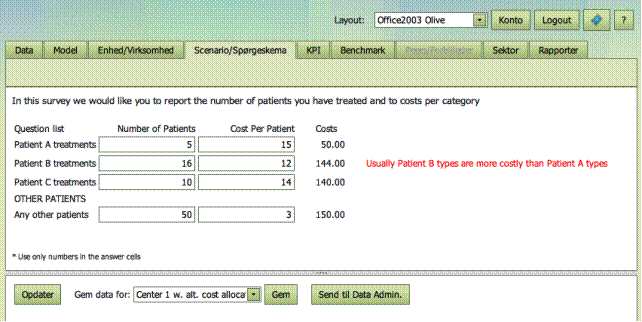
Scenarier/Spørgeskemaer
defineres i data-fanebladet,
Nøgletal-KPI
KPI = Nøgletal
Traditionel
benchmarking gør brug af en række nøgletal. I dette faneblad kan brugeren
undersøge disse ét afgangen og samtidig få en fornemmelse af en flerhed af
nægletal
Hvordan vælger man et
nøgletal-KPI
Nøgletallet skal
være defineret i det relevante datasæt, og brugeren kan vælge et nøgletal vha.
en drop-down menu.
Opsummering
Tabellen for oven
til venstre er en oversigtsstatistik.
For det valgte nøgletal angives gennemsnitsværdi mv på tværs af alle enheder / selskaber
for det valgte nøgletal, Enhederne i disse statistikker er som angivet i fanebladet
Potentielle Peers. Hvis der ikke er aktiveret nogen filtre og hvis ingen
enheder er blevet fravalgt i fanebladet Benchmark vil prøven bestå af
alle enheder som nøgletallet kendes for
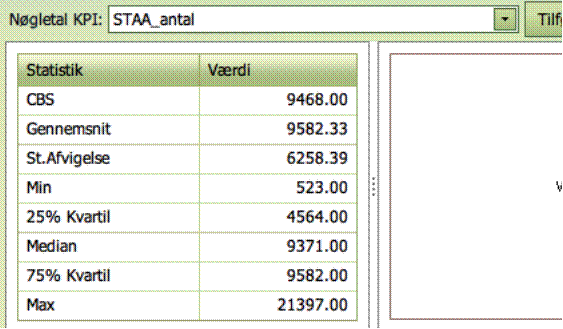
Oversigtsstatistikken
giver oplysninger om:
- Min Enhed, dvs. KPI-værdien for Min Enhed
- Gennemsnitsværdi, dvs. den (uvægtede) KPI-værdi, som de
forskellige enehders KPI-værdier varierer omkring
- St.Dev (standardafvigelse), dvs. et mål for
spredningen af KPI-værdier mellem enehderne
- Min (minimum), dvs. den mindste KPI-værdi
blandt selskaberne
- 25% Kvartil, dvs. den KPI-værdi som 25% af
enhederne ligger under og 75% ligger over
- Median, dvs. KPI-værdien som 50% af enhederne
er under og 50% er over
- 75% Kvartil, dvs. KPI-værdien som 75% af enhederne
ligger under og 25% ligger over
- Max (maksimum), dvs. den største
KPI-værdi i prøven
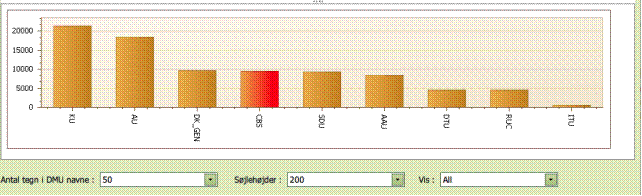
Enkelt KPI evaluering
af MinEnhed
I søjlediagrammet
under tabellen vises de enkelte KPI-værdier for alle Potentielle Peers.
Enhederne er arrangeret sådan, at de laveste KPI-værdier ligger til højre og de
høje værdier ligger til venstre. Min Enhed, hvis en sådan eksisterer, er
markeret med en rød sølje.
Multiple-KPIs
evaluering af MinEnhed
For at få et
overblik over flere nøgletal på en gang kan brugeren vælge at konstruere et
radar-diagram. Dimensionerne er diagrammet er valgt en ad gangen af brugeren
ved at markere et nøgletal og derefter trykke ”Tilføj Radar Graf”.
Radar-diagrammet viser ikke kun minimum og maksimumværdierne for hver
dimension, men også den gennemsnitlige KPI-værdi for prøven og værdien for Min Enhed.
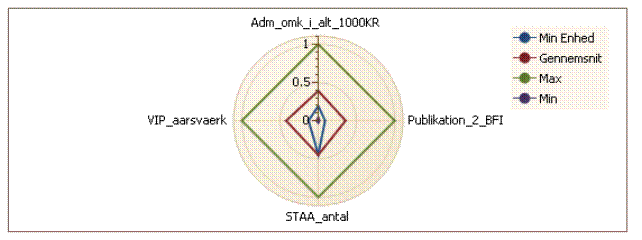
Radar-diagrammet
er konstrueret relativt til den maksimale nøgletalsværdi i hver dimension.
Derfor vil en værdi på fx 0.5 i en given retning svarer til 50% af den
maksimale værdi blandt alle selskaber. I illustrationen overfor vi kan se at
MinEnhed ligger omkring 0.5 i dimensionen ”STAA_antal”. På de andre dimension
er Min Enhed noget under gennemsnittet.
Zoom og trække in
IB-Win
Man kan nærstudere
søjlediagrammet ved at scrolle eller zoome.
Brugeren kan
scrolle med musehjulet for at zoome ind og ud i et diagram på samme måde som
man kan gøre i de mange andreWindows programmer.
For at aktivere
zoom-funktionen og gøre udvælgelsen mere præcis, skal man blot trykke
SHIFT-knappen ned. Derved ændre musepilen sig til et forstørrelsesglas. Man kan
derefter udvælge et område i et diagram ved at bruge den venstre museknap.

Hvis man først
har zoomet ind i en graf kan man også klikke i diagrammet og trække det til
højre eller venstre og op eller ned ved at bruge håndsignalet.

Justering (Trimning)
Navne på enheder
kan godt være meget lange, og det kan medføre at søjle-diagrammet ser lidt
underligt ud. For at håndtere dette kan man bruge Antal tegn i DMU navne i det nedre venstre hjørne, som begrænset
antallet af anslag der kan blive brugt i et navn.
Søjlehøjde
Søjlehøjden kan
også justeres til en passende højde ved brug af drop-down menuen Søjlehøjder.
Grupper
Sammenligningsgruppen,
dvs den gruppe af virksomheder som der laves statistik på, kan kontrolleres
vha. Peer-Gruppe drop-down menuen øverst til højre på siden. De tilgængelige
grupper er defineret i fanebladet Enheder: Potentielle Peers eller de
kan være Prædefineret i datasættet.
Det kan ofte være
en god ide at bruge en passende gruppe til at gøre KPI statistikkerne mere
relevante og til at justere illustrationerne, som vist nedenfor hvor det første
skærmbillede viser alle enheder, mens det næste kun viser de skoler fra samme
kommune som Min Enhed.
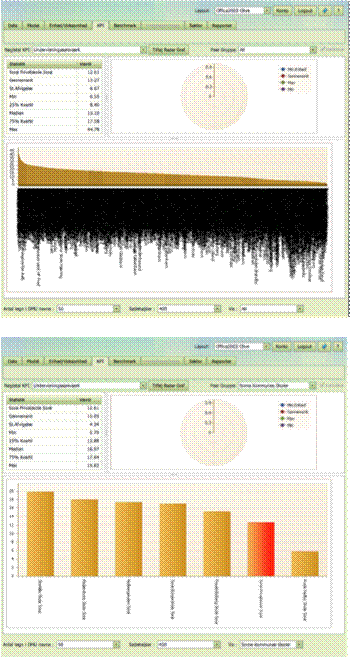
Rapportering
Du kan gemme
interessante resultater ved at bruge Rapport
værktøjet. Et pop-up vindue vil da blive aktiveret, hvor brugeren kan navngive
rapporten og bestemme hvilken del af KPI-skærmen, der skal inkluderes i
rapporten.

Brugeren kan senere
udvide rapporten ved at tilføje tabeller og diagrammer fra andre KPIs.
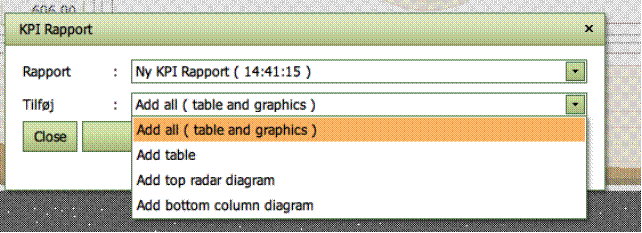
Rapporten kan til
enhver tid vises og downloades i forskellige formater i fanebladet Rapporter.
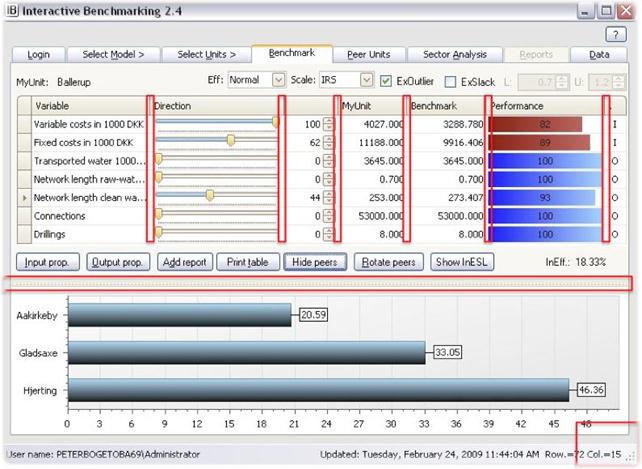
Benchmark
Benchmark er det
centrale faneblad. Her sammenlignes Min Enhed med en kombination af andre
enheder og brugeren kan på forskellig vis kontrollere hvordan disse
sammenligninger foregår
Benchmark tabel
Tabellen
sammenligner værdier fra Min Enhed, angivet i Aktuelle Værdi, med værdier hos Potentielle Peers eller en
kombination af Potentielle Peers, angivet i Benchmark. Dette svarer til at sammenligne et realiseret resultat
eller udvikling overfor et budget eller en plan.
Benchmarket er
konstrueret ved at sammenligned med alle Potentielle Peers og en klasse af
mulige kombinationer heraf. Blandt alle
disse sammenligninger (ofte er der uendeligt mange muligheder og kombinationer)
vælger programmet den sammenligning, som giver den størst mulige forbedring for
Min Enhed. De mulige sammenligninger kan syres via forskellige Benchmark kontroller,
se nedenfor.
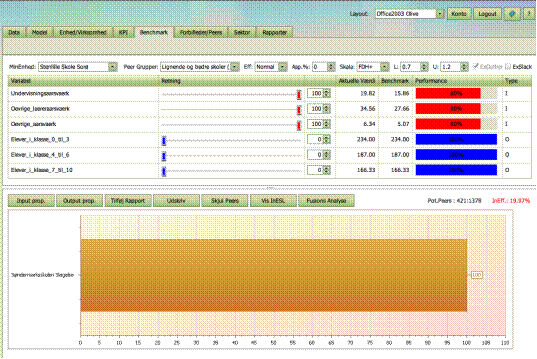
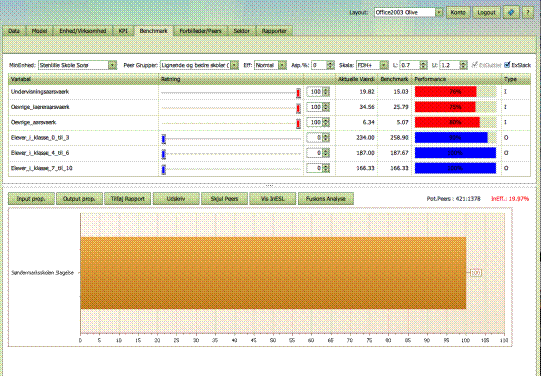
Benchmark
illustrationer
- De farvede søjler illustrerer sammenligningen
mellem Akutuelle Værdi og Benchmark
- De røde
søjler viser input-siden (omkostninger). De viser %-delen som
Benchmark bruger af Min Enheds værdi. 89 betyder for eksempel at
benchmarket kun bruger 89% af det Min Enhed bruger af det pågældende input.
Sagt på en anden måde, Min Enhed burde kunne spare 11% af den Aktuelle Værdi.
Korte røde søjler indikerer derfor store potentielle besparelser.
- De blå
søjler illustrerer outputs. De viser den procentdel Min Enhed aktuelt
producere af Benchmarkets output. 94 betyder for eksempel, at det er
muligt at øge outputs med 6%. Korte blå søjler indikerer derfor store
potentielle udvidelsesmuligheder.
Samtidige
forbedringer
Det er vigtigt at
bemærke de potentielle besparelser og udvidelsesmuligheder bliver beregnet
samtidigt. I eksemplet nedenfor har den analyserede enhed, en skole, mulighed
for at spare 8% på Undervisningsårsvækr, 16% på Øvrige lærertid, 16% på Andre
årsværk samtidigt med at også de forskellige output øges som vist.

Forbedringsretninger
De centrale
kontroller for Benchmarket er de horisontale
sliders. De lader dig introducere din egen søgeretning (præferencer,
strategi).
Hvis du er
interesseret i at lave større besparelser på et givent input frem for andre,
kan du trække dens slider mere til højre.
Hvis du ligeledes
er interesseret i at at øge mængden af et givent output mere end andre outputs,
kan du trække dens slider mere til højre.
Med andre ord, at
trække en slider til højre betyder, at du lægger mere vægt på denne dimension
og leder efter benchmarks, som har flere besparelser i denne retning (hvis der
er tale om et input) eller flere forbedringer i denne retning (hvis der er tale
om et output).
De forskellige
sliders fungere lidt ligesom et rattet i en bil bortset fra, at du nu kører i
et rum med mange dimensioner. Du kan vælge at køre mere imod en hvilken som
helst retning – inputs og outputs. Du kan også tænke på dem som lyd
kontrollerne i et musikanlæg, hvor du kan lægge mere vægt på nogle bestemte
frekvenser eller begrænse andre.
Frem for at bruge
de horisontale sliders kan du også bruge de op og ned pilene. De har den samme effekt, men de tillader at du
går over 100 eller under 0 (dvs. du er interesseret i at bruge flere af et
input eller i at reducere noget output). Tallenes betydning er forklaret i det
matematiske baggrundsmateriale som kan fås ved henvendelse til contact@ibensoft.com.
For de fleste
brugere er retningstallene dog ikke
så vigtige (på samme måde som det ikke er nødvendigt at forstå de detaljerede
kalibreringer i en bils styringsmekanismer for at være en god bilist). Det, der
hovedsageligt er brug for, er først og fremmest træning og en god ide om hvor
du gerne vil hen.
Proportionale
sammentrækninger og ekspansioner
Især to retninger
er populære og lette at forklare, nemlig 1) proportionale reduktioner af alle
inputs og 2) proportionale forøgelser af alle outputs. For at lette brugen af
disse to muligheder har vi tilføjet to specielle knapper til dette
- Input prop
- Output prop
som vist
nedenfor.

MinEnhed
Virksomheden der
bliver analyseret er afbilledet øverst til venstre som MinEnhed, og ved at
bruge drop down menuen er det let at bevæge sig fra analyse af én virksomhed
til en anden.

Peer Grupper
Sammenligningsgruppen,
dvs. gruppen af potentielle peers, kan også justeres direkte i Benchmark
faneblade ved at bruge Peer Gruppens træk ned menu. Denne menu er kun
tilgængelig, hvis nogle grupper af potentielle peers er blevet defineret i det
originale datasæt eller det er blevet gjort i den nuværende eller tidligere IB
sessioner vha. fanebladet Enheder: Potentielle Peers.
Vis peers
- Peers der danner baggrund for den
konstruerede benchmark bliver synlige, hvis du trykker på knappen Vis
peers.
- Navnene og vigtigheden af de forskellige
Peers er også afbilledet.
Fjern specifikke
peers
En meget nyttig
og populær mulighed er at klikke på en Peer:
- Dette vil fjerne den som potentiel peer og
benchmark vil derefter ændre sig.
- Dette er en effektiv måde at inkludere
eventuel subjektiv information du ligger inde med. Du ved måske på forhånd
at data for en given enhed er usikker eller at den bruger en anderledes
ledelsesfilosofi der ikke kan eller vil blive imiteret af MinEnhed.
- Hvis du er interesseret i at se flere
detaljer om de enkelte Peer Enheder før du beslutter om nogen skal
fjernes, kan du få alle detaljerne i fanebladet Peer Enheder.
- De eliminerede Peers kan blive tilføjet som
Potentielle Peers igen ved at bruge Fortryd Fravalg i fanebladet Enheder:
Potentielle Peers.
- Hvis du fortsætter med at fjerne Peers vil du
til sidst nå et punkt, hvor det ikke er muligt at opnå flere forbedringer.
Når det sker, vil Benchmark vise hvor mange ekstra ressourcer der skal bruges
eller hvormange serviceydelser vi bliver nødt til at skære ned på for at
kunne sammenligne med bedeste praksis blandt de resterende enheder.
- Hvis du fortsætte med at eliminere Peers kan
du også til sidst nå til et punkt, hvor det ikke at muligt at lave en
sammenligning.
InEfficiens
trappestige
Frem for at
eliminere Peers en ad gangen kan du også gøre dette på en automatisk måde ved
at trykke på knappen for InEfficiencs trappestigen InESL. Dette vil starte en proces, som successivt fjerner den mest
indflydelsesrige Peer indtil der ikke kan laves flere sammenligninger.
Ineffektiviteten vil falde i takt med at vi eliminerer flere og flere Peers.
Det endelige ineffektivitetsniveau er vist som en trappe.

InESL kan blandt
andet bruges til at få en forståelse af hvor robuste de estimerede
forbedringspotentialer er. Hvis InESL trappen er stejl, dvs. den falder
hurtigt, kan elimineringen af blot nogle enkelte Peer enheder væsentligt
reducere de estimerede forbedringer, og det oprindelige estimat vil derfor være
meget afhængigt at kvaliteten af de første Peers. Hvis InESL funktionen derimod
er flad, vil evalueringerne ikke være så afhængige af hvilke enheder vi bruger
i sammenligningen.
Elimineringsrækkefølgen
er bestemt af den enkelte Peers vægtning, som kan ses i den sædvanlige Vis
Peers illustration. På hvert trin elimineres den Peer som har størst vægt.
Skala (og
estimeringsprincipper)
De anvendte
estimeringsprincipper og de anvendte skalaantagelser kan ændres i rullemenuen
øverst til højre.
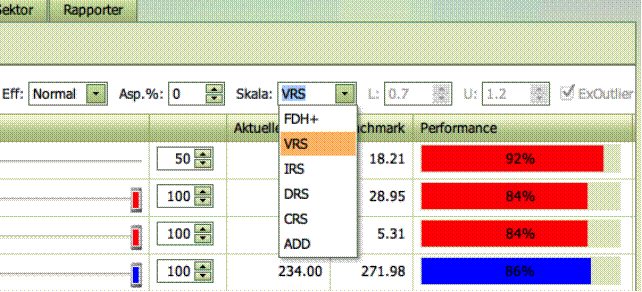
Alle mulighederne
FDH+, VVRS, IRS, DRS, CRS og ADD, er baseret på såkaldte ikke-parametriske
modeller (FDH og DEA), mens PAR muligheden er baseret på parametriske
specifikationer (SFA, økonometri). De førstnævnte modeller er baseret på ideen
om minimal ekstrapolation, mens den sidstnævnte fokuserer på at minimere støj
og ineffektivitet.
De fire klassiske
ikke-parametriske specifikationer laver følgende antagelser om skalaafkastet:
- Konstant skalaafkast (CRS) betyder, at vi ikke tror der vil være ulemper ved at være
hverken stor eller lille.
- Aftagende skalaafkast (DRS) betyder at der kan være ulemper ved at være stor, men
ikke ved at være lille.
- Voksende skalaafkast (IRS) betyder at der kan være ulemper ved at være lille, men
ikke ved at være for stor.
- Variabel skalaafkast (VRS) betyder at der kan være ulemper ved at være for lille og
ved at være for stor.
FDH+ specifikationen tillader en hvilken som helst form for fordel eller ulempe
af at blive større. Der kan for eksempel være fordele ved en lille størrelse,
ulemper ved mellemstore enheder og igen fordele ved store enheder. FDH metoden
bruger alene dataet til at finde disse egenskaber.
Når FDH er
aktiveret bliver det dog også muligt at lave yderligere antagelser om lokalt konstant skalaafkast. Dette
forklarer navnet FDH+. Ideen er, at
hvis en Enhed har brugt nogle bestemte inputs til at producere et bestemt
output, så kan vi også proportionalt skalere inputs og outputs med en hvilken
som helst faktor i intervallet fra L til
U. Oprindeligt er FDH specialtilfældet
hvor L=U=1.
ADD specifikationen er baseret på en antagelse om, at man altid kan gentage
hvad andre har gjort. Man kan derfor lave en virksomhed ved at lægge et hvilken
som helst antal selskaber sammen, baseret på logikken om at man altid kan
organisere et selskab som en række uafhængige mindre selskaber. ADD tillader
også mange kombinationer af fordele og ulemper ved at være stor eller lille,
men der er en logisk begrænsning på hvor mange ulemper der kan være ved at være
en stor enhed. ADD er også nogle gange kaldt FRH = Free Replicability Hull. For
flere detaljer se
Bogetoft, P. and
L. Otto, Benchmarking with DEA, SFA, and R, Springer 2011.
Egenskaberne for
skalafkastet ved PAR er kun
afhængige af egenskaberne fra den underliggende parametriske form. Normalt er den
mere begrænset end DEA specifikationen og med sikkerhed mere begrænset end FDH
specifikationen.
Efficiens
En anden kontrol
er Efficiens. Der er to mulige
indstillinger for denne.
- Normal efficiens betyder at den evaluerede enhed kan sammenlignes
med sig selv. I dette tilfælde er det derfor også altid muligt at finde et
benchmark, som er mindst lige så god som MinEnhed.
- Super efficiens betyder at den evaluerede enhed ikke
kan sammenlignes med sig selv. I dette tilfælde kan vi kun sammenligne med
bedste praksis ved andre. Hvis MinEnhed ikke er en ”bedste praksis” enhed
kan disse to indstillinger godt være sammenfaldende. Hvis MinEnhed derimod
er en sådan enhed, er det normalt ikke muligt at finde et benchmark som er
mindst lige så godt som MinEnhed. I sådanne tilfælde kan det være, at
Benchmarket bruger mere af nogle inputs eller producere mindre af noget
output. Fortolkningen af dette er, at MinEnhed kunne introducere denne
stigning i ressourceforbrug og/eller reduktion af serviceydelser uden at
miste dens status, som en bedste praksis enhed.
Super efficiens
er derved et mere informativt mål end Normal efficiens. Derudover er dens
begreb også meget nyttigt i for eksempel præstations-baserede
aflønningsprogrammer.

Ekskluder slack
Det beregnede Benchmark angiver de maksimalt mulige
forbedringer for MinEnhed i den
valgte Forbedringsretning. Udover
forbedringer i de proportioner, som er bestemt af Retningen, kan det også være muligt at lave individuelle
forbedringer, dvs. forbedringer i nogle af dimensionerne, men ikke i alle
retningerne. For at se de ekstra forbedringspotentialer i de forskellige
retninger skal du afkrydse ExSlack boksen.
Dette vil, hvis muligt, bestemme et nyt benchmark der bruger det samme antal
eller færre inputs og producere den samme mængde outputs eller mere end det
tidligere benchmark.
Ekskluder outliers
Hvis analyserne
af den foruddefinerede model indikerer, at nogle af observationerne er
potentielle outliers, kan man få dem angivet i data-filen. Brugeren kan også
vælge om han ønsker at inkludere eller ekskludere disse afvigende
observationer, når benchmarket bliver beregnet. Standard indstillingen er at
potentielle outliers bliver ekskluderet, og afkrydsningsfeltet ExOutliers er derfor normalt krydset af
fra starten.
Aspiration
Aspirationsrullemenuen
Asp.% gør brugeren i stand til at lave
benchmarks mod standarder der er x% over eller under bedste realiserede
praksis.

Hvis
aspirationsniveauet for eksempel er sat til -10% betyder det at vi vil stræbe
efter kun at være 10% under produktionsfronten for bedste praksis. Dette er kan
også let bruges til at tage højde for forventede produktivitetsforbedringer i
virksomheden, fx kan en 2% produktivitetsforbedring i løbet af det næste år
indberegnes ved at sætte et 2% aspirationsniveau baseret på data fra i år.
Aspirationsniveauet
er i absolutte termer. Hvis en brugers aspiration er at være blandt de 10%
bedste virksomheder målt på performance, kan man lave en sektoranalyse baseret
på proportional output reduktion og aflæse den øvre 10% fraktil af
effektivitetsfordelingen i fordelingsdiagrammet. Hvis denne for eksempel er
1.17 betyder det, at et aspirationsniveau på 17% svarer til at være blandt de
10% bedste målt på performance.
Aspirationsniveauet
påvirker ikke modellerne, hvis der ikke er noget output.
Fusionsanalyse
Fusionsanalyse-knappen
aktiverer et fusionsanalyse-modul i et pop-up vindue. Analysen estimerer
potentielle gevinster ved en fusion og opdeler disse i tre kategorier; læring,
harmoni og størrelse.
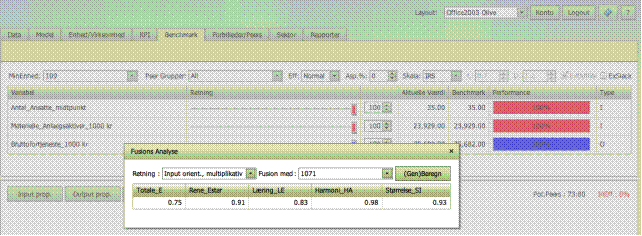
Analysen omhandler
en hypotetisk fusion of MinEnhed,
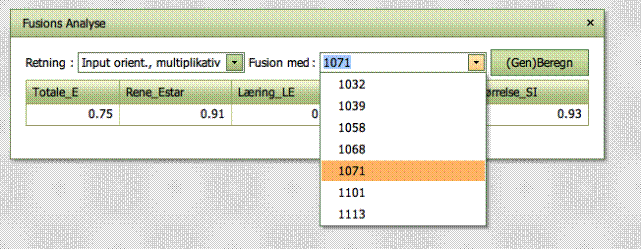
som vist øverst til venstre på skærmen, og en fusionskandidat, som er
specificeret i drop down boksen Fusion
med, der findes i fusionsanalysens vindue. Det er derfor meget let at
ændre, hvilken fusion der skal analyseres.
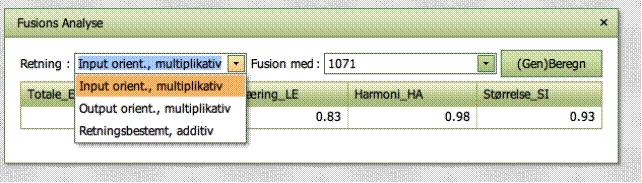
Opdelingen af
gevinster kan gøres i forskellige retninger, nemlig input-baseret og
multiplikativ, output-baseret og mulitiplikativ, samt retningsbestemt og
additiv, hvor retningen bliver specificeret af brugeren i Benchmark fanebladet.
Den generelle
fortolkning er dog stadig den samme:
- Total_E er den totale potentielle gevinst ved
en fusion og beregnes som alle mulighederne for forbedring af et selskab
der opererer som om den har to afdelinger med samme mængde inputs og
outputs som henholdsvis MinEnhed og fusionskandidaten oprindeligt har.
- Ren_Estar er den potentielle gevinst ved en fusion,
når mulighederne for individuelle forbedringer i de fusionerende selskaber
er blevet fjernet. Den repræsenterer derfor potentielle gevinster fra et
muligt samarbejde der rækker ud over at dele bedste praksis ideer.
- Læring_LE måler hvad de enkelte selskaber i
fusionen kan få ud af at lære bedste praksis. Det er læringseffekten som
bliver fjernet, når man går fra totale potentielle gevinster til rene
fusionsgevinster.
- Harmoni_HA eller mix effekten måler gevinsten,
hvis de fusionerende parter delte ressourcer (input) og forpligtelser
(output), men forblev selvstændige enheder. Den måler, hvad der kan opnås,
hvis de ”fusionerende” parter omfordeler inputs og outputs mellem sig. For
at aktivere harmoni (mix) effekten må man dybest set tillade bindende
kontrakter mellem de samarbejdende parter, men i princippet er det ikke
nødvendigt at lave en fuld fusion..
- Størrelse_SI effekten måler gevinster eller tab ved
at have en fusioneret virksomhed, der er større end de fusionerende
enheder.
Fortolkningen er
derudover afhængig af retningen
- Input multiplikativ. Her repræsenterer (1 – Værdier) en
gevinst. For eksempel betyder HA = 0,8, at en omfordeling af input og
output kan lede til en 1 – 0,8 = 20% besparelse. Tilsvarende betyder SI =
1,2 at det er et tab på 20% ved
at drive den fusionerede enhed i en større målestok.
- Output multiplikativ. Her repræsenterer (Værdi – 1) en
gevinst. Dvs. HA = 1,3 betyder for eksempel at alle outputs kunne have
været udvidet med 30% uden at bruge flere inputs, blot ved at omfordele
inputs og outputs mellem de to parter.
- Retningsbestemt additiv. Her måler vi forbedringer i bundter
af inputs og outputs. Et bundt svarer til de anvendte inputs og producerede
outputs i de fusionerende parter som er multipliceret med de
retningsbestemte vægte. Igen har vi, at en positiv værdi repræsenterer en
gevinst og en negativ værdi repræsenterer et tab.
De multiplikative
dekomponeringer er
E = LE * Estar = LE * HA * SI
mens de additive dekomponeringer
er
E = LE + Estar = LE + HA + SI
Detaljerne i
disse dekomponeringer er beskrevet i
Bogetoft, P.,
Efficiency Gains from Mergers in the Health Care Sector, Part B: Modelling and
Part C: Implementation, Research Papers 2008:07 and 2008:08, NZa, The
Netherlands.
Bogetoft, P. and
D. Wang, Estimating the Potential Gains from Mergers, Journal of Productivity
Analysis, 23, pp. 145-171, 2005
Bogetoft, P. and
L. Otto, Benchmarking with DEA, SFA, and R, Springer 2011
Tilføj rapport
Når du har en
interessant benchmark, kan du lave en rapport – fx så du kan huske dine
resulater eller vise dem til andre. Tilføj
Rapport funktionen kan bruges gentagne gange under forskellige antagelser
om benchmark
Når vi har
tilføjet mindst én rapport bliver fanebladet Rapporter aktiv. Dette faneblad indeholder et
lager med rapporterne, som du senere kan redigere og udskrive.
Print tabel
Du kan også
udskrive sammenligningstabellen ved at trykke på Print tabel. Dette giver et billede, der kan gemmes som en pdf-fil.
Peer Enheder /
Forbilleder
Peer Enheder
Fanebladet Peer
Enheder giver yderligere oplysninger om det beregnede Benchmark. Du får
- Peer enhedernes navne
- Deres relative betydning (vægtene summer op
til 100)
- Deres absolutte vægte (som ikke nødvendigvis
summer til 100)
- Et billede af Peer Enhedernes struktur
sammenligned med Min Enhed.
Peer søjler
Den øverste
illustration svarer til Peer illustrationen i Benchmark fanebladet. Du kan også
klikke Peers væk og se en genberegning som i Benchmark fanebladet.
Radar graf
Radar grafen
viser modellens input og output for Min Enhed og for de andre Peers. De giver
derfor en første fornemmelse af sammenligneligheden mellem Min Enhed og de
foreslåede forbilleder.
Yderligere Peer
information
Det nederste
vindue viser
- Eventuel ekstra information om enhederne
- Øverst vises inputs og outputs bag
beregningerne
- Desuden vises alle øvrige oplysninger der er
tilgængelige om Peer Enhederne.
Sektor Analyse
Sektor Analyse
I fanebladet
Sektor kan du
- Lave benchmark for alle Enheder i sektoren
under de samme forudsætninger, som bruges i Benchmark fanebladet.
- Gemme resultaterne i en Excel-fil
- Illustrere resultaterne i fem forskellige
graftyper; Tæthed, Fordeling, Sorterede InEff, Indflydelse og
Efteranalyse.
InEfficiens Scorer
I den øverste
tabel vises de beregnede InEfficiencer for alle enhederne i sektoren.
- De måler det antal gange de forskellige
selskaber kan forbedre deres præstationer i samme retning som du anvendte
i Benchmark fanebladet
- Store værdier indikerer derfor InEfficiens
Forudsætninger
- Evalueringerne foretages i Retningen (% s),
som er valgt i fanebladet Benchmark.
- Beregningerne er relative i forhold til den
teknologi, der anvendes i fanebladet Benchmark.
Lagring og
illustration af resultaterne
Resultaterne kan
gemmes i en Excel-fil, som du så kan arbejde videre på i andre sammenhænge.
Grafer
IB har fem
muligheder for at illustrere resultaterne, nemlig som
- Tæthed
- Fordeling (Kumulativ)
- Sorterede InEfficiencer
- Indflydelse
- Efteranalyse
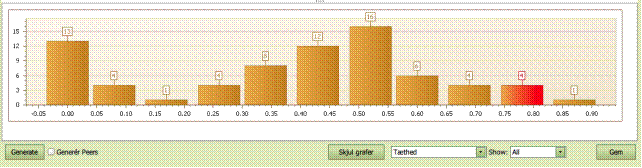
Tæthed
Denne
illustration viser InEfficiencerne i et sædvanligt histogtam
- Ved at klikke på en af søjlerne får du listen
af enheder med tilhørende InEfficiencer vist i tabellen ovenfor.
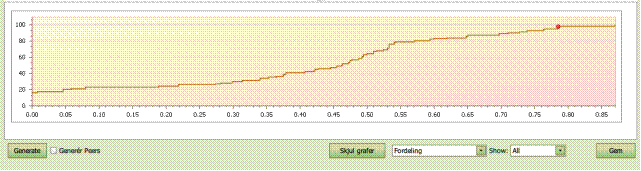
Fordeling
Dette er den
sædvanlig kumulative fordeling af InEfficiencerne.
- Enheden vi fokuserer på, Min Enhed, er
markeret af med rødt.
- Den lodrette akse viser fraktilerne, dvs den
% del af selskaberne som er dækket, og den vandrette akse viser værdien af
selskabernes InEfficiencer.
Sorterede
InEfficienser
I denne graf
ordnes InEfficerne i faldende orden, og navnene på de tilsvarende selskaber
vises på den vandrette akse.
- Min Enhed er som sædvanligt markeret med
rødt.

Indflydelse
Indflydelsessgrafen
viser InEfficiencerne på den vertikale akse og værdien af enhedene på den
vandrette akse.
- Hver kolonne repræsenterer en Enhed.
- Bredden af søjlen er proportional med en valgt
faktor.
- Man kan ændre denne faktor ved hjælp af drop-down
menues
- Enheden vi fokuserer på, Min Enhed, er
markeret med et rødt mærke i den tilhørende kolonne.
- Bemærk: Dette er nyttigt for at få en ide om,
hvor der er InEfficiens i sektoren, idet InEfficiens i store enheder vil
blive repræsenteret af bredere søjler. På denne måde bliver området
proportionalt med det sociale tab.

Efteranalyse
Grafen for efteranalyse
plotter InEfficienserne mod andre tilgængelige variable.
- Du kan vælge hvilken variabel du vil at
plotte imod.
- Plottet giver dig en idé om udeladte
variabler, der kan have en systematisk indvirkning på ineffektivitet.
- Det kan bruges (i grove træk) til at rette op
på de beregnede InEfficienser, hvis der findes en klar sammenhæng mellem
disse og nogle af de udeladte inputs, outputs eller omgivelsesvariable.

Zoome og trække i
IB-Win
Graferne i Sektor
fanebladet kan undersøges i flere detaljer ved at zoome og flytte grafen rundt.
Denne funktionalitet er kun mulig i IB-Win.
Brugeren kan scrolle
for at zoome ind og ud i et diagram på samme måde som man zoomer i standard
Windows-programmer.
For at aktivere
zoom-funktionen og gøre valget mere præcist skal du blot trykke på SHIFT-tasten.
Musemarkøren ændres da til et forstørrelsesglas. Herefter kan du vælge en
region af et diagram ved at bruge venstre museknap.

Når der er zoomet
ind på en bestemt del af grafen kan brugeren også flytte rundt på den del af
grafen som vises ved brug af håndsymbolet.
![]()
Sektorrapporter
Du kan opsamle
interessante resultater ved hjælp af Rapport.
Et pop-up vindue bliver hermed aktiveret. I denne kan brugeren navngive
rapporten og kan bestemme hvilke dele af resulaterne i Sektor fanebladet, der
skal gemmes. Nye interessante sektor resultater kan senere placeres i en ny
sektor rapport eller tilføjes til en eksisterende rapport. Rapporten kan til
enhver tid blive vist og downloadet i forskellige formater under fanebladet
Rapporter.
Generér Peers
Peers fra alle
enheder i en DEA- eller FDH-analyse kan genereres og vises i Sektor-tabellen
ved at afkrydse ”Generér Peers” feltet.

Dynamisk
Fanebladet Dynamisk giver mulighed for at
analysere ændringer over tid.
Hvis datasættet
indeholder data fra forskellige perioder kommer fanebladet Dynamisk til syne i
IB. Det tillader brugeren at beregne Malmquist produktivitets index, i
programmet simpelthen kaldet Total, såvel som en dekomponering af dette i
Indhentning og Frontskifte indices.
Tre
dynamiske index
Fortolkningen af
disse indices er som følger:
Total måler den samlede forbedring i et selskabs præstation fra en periode til
den næste. En værdi på 1.1 tyder fx på, at virksomheden har øget output pr
input med 10% i forhold til sidste periode.
Indhentning måler i hvilket omfang et selskab er kommet
tættere på bedste praksis. En værdi på fx 1.1 tyder på, at virksomheden har
forbedret sine resultater i forhold til bedste praktisk, altså
produktionsfronten, med 10%. Selskabet er altså kommet tættere på de mest efficiente
selskaber i branchen.
Frontskifte er forbedringen af bedste praksis fra den ene
periode til den næste. En værdi på fx 1.2 betyder, at selv blandt de mest
effektive virksomheder har det været muligt at reducere input med 20% eller
udvide output med 20%.
Bemærk at der
gælder
Total = Indhentning x Frontskifte.
dvs den totale
forbedring er produktet af indhentningen og frontskiftet. Hvis de bedste
selskaber fx er faldet tilbage med 10% og MinEnhed har forbedret sig 5% i
forhold til de bedste, er den totale effekt 1.05x0.9=0.945 med den fortolkning,
at MinEnhed reelt er blevet 5.5% dårligere til at omsætte input til output. Selskabet
er godt nok kommet tættere 5% tættere på de mest effektive, men da disse er
faldet 1% tilbage betyder det jo, at også selskabet er faldet tilbage med ca
5%. Hvis på den anden side MinEnhed har forbedret sin position i forhold til de
bedste med 20% og de bedste har forbedret sig med 10%, så har MinEnhed reelt
forbedret sig med en faktor 1.2x1.1 = 1.32, dvs med 32%.
Tabeller
og grafer
De tre indices
beregnes og vises både i en tabel og i grafer og for såvel MinEnhed som i
gennemsnitsform for alle enheder i analysen.

Brugeren kan
vælge hvilken DEA model, som skal anvendes i beregningerne, jvf Skala, hvilket
selskab, som skal vises direkte, jf. MinEnhed, og hvorvidt der skal anvendes
input eller output orienterede efficiensmål.

Brugeren kan også
selv vælge hvilken graftype og hvilken farveskala, som skal anvendes.

Dynamiske
analyser kan ikke kun anvendes til at undersøge, hvordan selskaberne udvikler
sig over tid. Man kan også anvende Dynamisk til at analysere andre forskelle i
den måde selskaberne arbejder på. Man kan fx opdele selskaberne efter
geografiske forskelle og studere, hvorledes bedste praksis afhænger af den
geografiske placering, eller man kan opdele efter ejerskabsform og se, hvordan
dette påvirker selskaberne, herunder vurdere, hvad et selskab kan vinde ved at
ændre ejerstruktur.
De
anvendte formler
Lad os slutte med
nogle mere præcise og formelle definitioner af de forskellige indices. I den
videnskabelige litteratur, refererer produktivitet til ændringer over tid. Hvis
output ændres mere end input siger vi at produktiviteten øges. I dynamiske
analyser anvendes ofte Malmquist målet og dets dekomponering. Malmquist måler
ændringen fra den ene periode til den næste som det geometriske gennemsnit af
selskabets resultater i forhold til den tidligere og nuværende teknologi
Mere konkret kan
vi lade Ei(s,t) være et mål for Virksomhed i’s performance i periode
s vurderet i forhold den teknologi, som foreligger til tid t. E kan således fx
måle den proportionale reduktion i Virksomhed i’s input i periode s hvis
virksomhed vurderes i forhold til teknologien som den ser ud i periode t. E
kunne også være den inverse værdi af de mulige proportionale forøgelser af alle
output.
Selskab i’s
forbedring fra periode s til t kan vurderes vhja Malmquist index Mi(s,t)
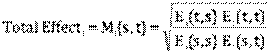
Intuitionen bag
dette index er følgende: Vi ønsker at sammenligne selskabets præstationer i
periode t med dets præstationer i periode s for at vurdere fremskridtene.. Vi
kan vurdere præstationerne i forhold til enten teknologien, som den så ud i
periode s eller t. Da begge reference teknologier for så vidt kan være lige
gode tager vi det geometriske gennemsnit af de to vurderinger af fremskridtene.
Hvis selskabet har forbedret sig er tællerne større en nævnerne, dvs M er
større end 1. En værdi på fx M = 1.2 betyder, at selskabet har
forbedret sig med 20%, fx via et fald på 20% i ressource forbruget samtidigt med
at service niveauet er fastholdt.
Ændringen i
præstationsniveauet kan skyldes to forhold, som muligvis forstærker hinanden,
muligvis modvirker hinanden.
Den eneste faktor
er såkaldt tekniske ændringer, technical changes TC, som handler om ændringer i
produktionsfronten. TC>1 svarer til teknologiske fremskridt og TC<1 til
teknologiske tilbagefald. Den anden faktor er såkaldte efficiens ændringer, efficiency
changes EC, som måler indhentning relativ til bedste praksis. EC>1 betyder,
at selskabet er kommet tættere på fronten og EC<1 betyder at selskabet er
faldet tilbage i forhold til fronten.
Dekomponeringen
fremkommer ved en simpel omskrivning af Malmqusit formlen
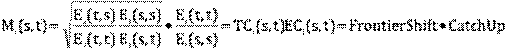
Malquist målet og
dets dekomponering er nyttig når man vil undersøge den dynamsike udvikling fra
en periode til den næste. Når man sammenligner på tværs af flere en to perioder
skal man være forsigtig. Man kan ikke på simpel vis akkumulere ændringerne.
Malmquist indexet opfylder nemlig ikke i almindelighed M(1,2) x M(2,3) = M(1,3)
– dvs fremskridte fra periode 1 til 3 er ikke bare et produkt af fremskridte
mellem periode 1 og 2 og periode 2 og 3 (medmindre ændringerne er såkaldt
Hicks-neutrale). Denne ”skavank” er meget almindelig blandt dynamiske index og
hvis den tillægges stor betydning må man i stedet anvende index med fast
basis, hvor man hele tiden måler
mod den samme teknologi.
Rapporter
Fanebladet Rapporter indeholder henvisninger til
Rapporterne som er genereret i KPI, Benchmark og Sektor fanebladene.
Rapporterne er navngivet som standard i overensstemmelse med den kalender tid,
hvor de blev lavet.
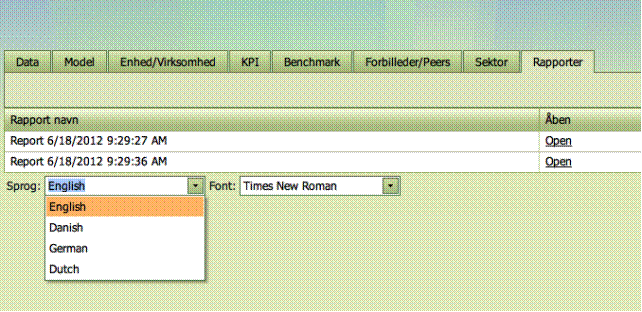
Rapport formater
Skrifttypen der
anvendes i rapporterne kan ændres til en hvilken som helst tilgængelige
skrifttype fra Windows-systemet.
Når en rapport er
åbenet kan den gemmes i forskellige formater, hvilket giver dig mulighed for at
lave de endelige rapporter i PDF-format med det samme, samt at gemme rapporter
i redigerbare formater som HTML, MHT, RTF, Excell, CSV, tekst og billede.
Sidst men ikke
mindst, kan brugeren vælge rapportens sprog. Version 2.7 understøtter både
engelske, danske, tyske og hollandske rapporter.

Rapport indhold
De automatisk
genererede Benchmark-rapporter er skrevet som selvstændige rapporter.
Informationen inkluderet i disse rapporter er:
- MinEnhed
- Anvendte præstations indikatorer
- Præstations mål (retning)
- Benchmark med og uden slack
- Samlet InEfficiens indeks
- Peer enheder og deres relative betydning (når
relevant)
- Robusthed af evalueringerne (InESL)
- Model antagelser
- Detaljer om faktiske Peers
- Korte bemærkninger om Interaktive
Benchmarking IB ®
Den typiske
størrelse på en rapport er 9-12 sider.
Rapporterne
justeres automatisk for at afspejle den specifikke kontekst (Model, Enhed
osv.).
KPI- og
Sektor-rapporter er mere simple og indeholder de centrale grafer og tabeller.
Data
Data
Fanebladet Data
indeholder de data, som aktuelt anvendes, i IB-Win, eller som er til rådighed,
i IB-Web.
I IB-Web kan du
gemme flere datasæt og vælge hvilket sæt der skal analyseres ved at trykke på
den tilhørende grønne pil. Du kan også downloade datasæt og slette dem.

Indlæsning af et nyt
datasæt i IB-Win
Det er muligt at
indlæse en ny datasæt ved hjælp af knappen Indlæs
ny data.
- Den nye data skal være i et Excel-regneark og
være korrekt formateret for at kunne indlæses.
- Hvis en ny datasæt er korrekt indlæst vil
programmet automatisk vender tilbage til login-siden og en normal IB
session kan begynde.
Indlæsning af et nyt
datasæt i IB-Web
Det er også
muligt at indlæse en ny datasæt ved hjælp af to metoder i IB-Web.
Metode 1 lader dig
uploade en forudspecificeret xls workbook. Disse datasæt skal være angivet som
Excel-regneark og være korrekt formaterede.
Metode 2 giver
dig mulighed for at definere et datasæt med hjælp fra programmet. Du behøver
altså ikke vide præcist hvordan man skal formatere data in en xls workbook.
Oprettelse af et nyt datasæt på denne måde guider brugeren gennem de nødvendige
skridt.
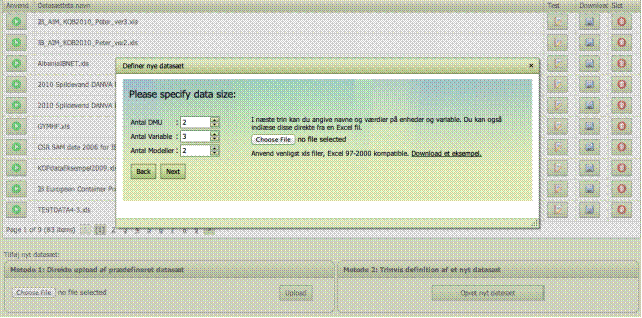
Forberedelse af et
nyt datasæt
Før et nyt
datasæt kan indlæses direkte, må det være korrekt formateret.
Det nye data skal
være formateret i Excel og må indeholde op til 11 ark:
- DMU Data
- Model Data
- Scenarie / Spørgeskema
- Login Inf
- Sponsor
- Outliers
- Peer Grupper
- Vtrans
- Historiefortælling
- Dynamiske data
- Format
- PAR Data
For at forberede
en ny data-fil kan det være en god ide at tage et kig på indholdet af et
testdatasæt.
Xls workbook
består som nævnt af et antal ark som indeholder forskellige typer af
information. Man behøver ikke andre ark end DMUData arket, men kan opnå ekstra
funktionalitet ved at specifere indholdet i et antal af de øvrige ark.
DMUData
- I DMUData arket angives søjlerne DMU, Name,
og dernæst alle variablene. Forskellige rækker svarer til forskellige
Enheder / Virksomheder.
- DMU er enhederne fortløbende nummer
- Name er enhederne navne og navn og
derefter alle variable i de følgende søjler
- Variabel-navne er de navnde som bruges til at
betegne input og output mv.
- Det betyder ikke noget om du bruger komma
eller punktum som decimaltegn
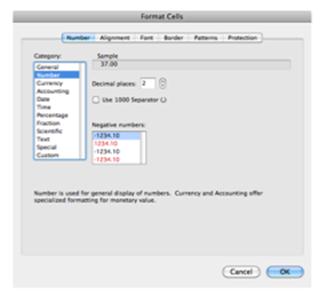
- I DMUData arket, skal alle variable-kolonner
være formateret som tal. DMU- og Navne-kolonner er formateret som
"Generel".
ModelData
- I ModelData arket defines de præ-definerede
modeller
- Første kolonne er No og specificere et fortløbende modelnummer
- DefaultCalcType er skalaafkastet med mulige værdier FDH,
VRS, IRS, DRS, CRS, og ADD
- Name er et modelnavn, der vil komme op i fanebladet
Model: Prædefineret.
- Description er den tekst, som tilhører en given
model, og som vises når en præ-defineret model er valgt i Model:
Prædefineret fanebladet
- De resterende søjler er til alle variablene. Søjerne
tildeles variablenes navne, og
i en modelrække specificeres de tilhørende variable som I (input), O
(output), R (read-only) eller L (en hvilken som helst variabel, også navne)..
- I ModelData, bruges formateres alle søjler
som ”Text” med undtagelse af Description søjlen, som skal formateres som
”General”.
Scenarie /
Spørgeskema
Scenarie /
Spørgeskema i IB-Web bliver defineret ved at tilføje et faneblad kaldet
Scenarie. Hvis der ikke findes sådanne faner i data-filen, vil der heller ikke
være en Scenarie / Spørgeskema fane i det IB Web-systemet brugeren anvender.
Scenarier / Spørgeskemaer er tilknyttet modeller og skal derfor være
nummererede. Scenarie_1 refererer model 1, Scenarie_2 til model 2 osv.
Et eksempel på et
spørgeskema er vist i xls-filen sammen med spørgeskema-siden i IB-Web systemet
nedenfor. Vi ser, at der to modeller med scenarier / spørgeskemaer (Scenarie_1
og Scenarie_2). Nye data gemt af bruger i forbindelse med definitionen af en
ny enhed i model 1 vil være gemt i Scenario_1_11, idet den nye enhed bliver
nummer 11 i DMUData arket.

I definitionen af
basis Scenariet / Spørgeskema, som vist i det første billede, vil
kolonneoverskrifterne være fastesatte på forhånd og defineret på følgende måde;
- ID nummererer spørgsmålene
- Question kolonnen indeholder først teksten,
der vil blive vist som en overskrift på brugerens skærm, og dernæst
formuleringen af de spørgsmål, som en bruger skal besvare
- Variable name kolonnen definerer variabelnavnene
på de resultater, der hører til de forskellige spørgsmål. Disse er de
navne, der anvendes internt i programmet, og som også anvendes hvis
brugeren vælger at Selv-definere en model.
- Answer1, ... kolonner er der, hvor brugeren skal
afgive et svar. Overskriften på en given kolonne fremgår af anden række,
og brugeren kan udfylde værdier i de tilhørende celler. Hvis en bruger
ikke skal udfylde en celle, kan han fjerne cellen ved hjælp af koden
[Skjul]. Man kan frit vælge antallet af Svar-kolonner.
- Result kolonnen indeholder først en
overskrift og dernæst en definition af de beregnede værdier, der vil blive
vist til brugeren, når han opdaterer Spørgeskema-siden. Enhver xls-formel
kan bruges til at definere disse værdier. Værdierne i Resultat-kolonnen er
de værdier, der er hører til de tilsvarende variable anført i Variable name
kolonnen og som anvendes i programmet.
- NewVariable1, ... kolonner tillade bruger at definere
andre afledte værdier, der kan blive anvendt i modellerne. Den afledte
værdi vil blive tildelt variable navne som angivet i anden række, og
formlerne til disse beregninger vil være angivet i den tredje række.
- Notification kolonnen bruges til at definere
nødvendige datavalideringsregler. Logiske tests baseret på nogle af de
indsendte eller udledt værdier vil normalt blive introduceret her, som
vist i eksemplet. Advarselsmeddelelser vil blive vist i rødt.
- Description kolonnen indeholder i anden række den
tekst, der vil blive vist på skærmen, før selve spørgsmålene kommer.
- Remark kolonnen indeholder i anden række den
tekst, der vil blive vist efter spørgsmålene.
- Provider Email angiver udbyderens e-mail. Hver gang
brugeren sender ny information til spørgeskema administrator vil det blive
sendt til denne e-mail.
Værdierne der kan
blive anvendt i Benchmark er de værdier, der er nævnt i kolonnerne NewVariable1,
New Variable2, samt i kolonnen Variable Name. For at kunne bruge disse værdier
skal de være indført i Data-fanebladet og Model-fanebladet som vist i den anden
figur ovenfor, hvor vi har gemt værdier for Center 1 og Center 1 med
alternative omkostningsfordeling. De er blevet indført ved at brugeren direkte
aktiverede knappen Gem.
Når brugeren Sender data vil Spørgeskema-udbyderen
få direkte besked på en e-mail fra interactivebenchmarking@gmail.com med
titlen Spørgeskema færdigt! hvortil der er et link, som Udbyderen kan bruge til
at hente de nye data.
Udover de mest
centrale data, dvs. informationen fra kolonerne Answer1, Answer2, …, er der
også information om hvem, der har givet oplysningerne, og hvilken enhed disse
henviser til. Et eksempel er vist nedenfor. Vi kan her se, at data er blevet
send fra brugeren Peter, og at det refererer til Enheden kaldet Center 1 w.
Alt. cost allocation.

LoginInfo in IB-Win
- Du kan du vælge ikke at indsætte nogen form
for information i LoginInfo. Dette vil give dig fuld fleksibilitet, samt
give dig mulighed for at starte programmet uden et brugernavn og en
adgangskode.
- Alternativt vil Login bestå af brugere,
disses adgangskoder og indikatorer for deres adgang i niveauer (1, ...,
10).
- Adgangsniveauet bestemmer, hvad programmet
vil vise, såsom hvilke faner og underfaner (og vinduer) der vil være til
rådighed for den enkelte bruger.
Sponsor in IB-Win
Sponsor arket
indeholder Name information, dvs. en overskrift til Interaktiv Benchmarking; fx
"Vand" der vises i blåt over Interaktiv Benchmarking i Login fanebladet.
Arket indeholder
også oplysninger om sponsorens URL.
Outliers
Outlier-fanebladet
giver dig mulighed for at præcisere et sæt af potentielle outliers for hver
model. Den første række indeholder modelnavnet, og de potentielle outliers i
den tilsvarende model er givet ved hjælp af enhedernes navne nedenunder.
Når ExOutlier er
afkrydset i Benchmark-fanebladet vil alle beregningerne i fanebladet blive
udført uden outliers, dvs. disse outliers får ikke lov til at påvirke ”bedste
praksis”. I eksemplet nedenfor udelukker vi kun én enhed i modellen ”Distr. D
& V Model 1x4”, nemlig "Aabenraa Forsyning Service A / S", mens
vi i modellen ”Distr. Total Cost Model 2x4” også udelukker "Grindsted
Vandværk A.m.b.a."

PeerGroups
Potentielle Peer
grupper behøver ikke kun at blive defineret under en session. De kan også
foruddefineres ved at indføre en ”Peer Gruppe”-fane i Data xls worksheet.
Navnet på en gruppe er givet i første række, og Enhederne i gruppen angives med
deres navne i rækkerne nedenfor. I fanerne KPI/Nøgletal og Benchmark kan
brugeren scrolle gennem listen af
definerede grupper og finde dem, som er særligt relevante. I eksemplet
nedenfor er en Peer Gruppe ved navn ”Frederiksberg Kommune” defineret i den
anden kolonne. Vi kan se at den består af skolerne Lindevangskolen,
Søndermarkskolen, ..., Skolen in the Søerne.

En mere avanceret
form for Peer Grupper er Betingede Peer Grupper. De defineres ved hjælp af
R-kode. Derved kan brugeren definere grupper der bl.a. afhænger af den enkelte
enhed, Min Enhed, som bliver analyseret. Sådanne Peer grupper er markeret med
et specielt tegn i programmet som vist nedenfor.
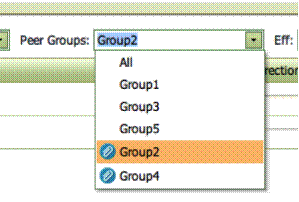
For at definere
Peer Grupper, som er baseret på R-kode, bliver brugeren nødt til at introducer et
faneblad kaldet PeerGroupConditions” som vist i eksemplet nedenfor.

I dette eksempel
er der defineret to R Peer Grupper. Gruppe 2 er simpel og består af Enhederne
1, 3, 4 og 7, mens Gruppe 4 er mere kompliceret og er udledt ud fra en ægte
R-loop. Reglerne for at lave R-baserede ”Betingede Peer Grupper” er følgende:
Som input til den
R-baserede procedure kan man anvende
ib_DMUData = en
matrix med data der er præcis ligesom data i DMUData-fanebladet fra xls-arket
ib_MyUnit = DMU
nummeret for Min Enhed
ib_RTS =
skalaafkastet som bliver brugt i modellen
ib_benchmarkDirection
= Retningen i input-output rummet, hvor IB søger efter et benchmark
Bemærker endvidere,
at
ib_InputNames = navnene på inputs i modellen
ib_OutputNames = navnene på outputs i modellen
Disse kan også
skrives som
ib_InputNames<-colnames(ib_selectedInputs)
ib_OutputNames<-colnames(ib_selectedOutputs)
For output
genereret mest
ib_UserConditionalPeers = en
liste (vektor) af DMU numre, der udgør Peer Gruppen for den valgte ib_MyUnit.
Som et eksempel
på en kode kan vi antage, at vi har data fra flere år og er interesserede i at
bruge 2010-grænsen. Vi ønsker også at udelukke virksomheder, der outliers i
forhold til grænser, der svarer de kriterier den regulator BNetzA anvender.
Scriptet kan da se således ud:
# WE INITIALLY
DEFINE
ib_InputNames<-colnames(ib_selectedInputs)
ib_OutputNames<-colnames(ib_selectedOutputs)
# FIRST SET OF
FILTER
full_data <-
complete.cases(ib_DMUData[,c(ib_InputNames,ib_OutputNames)])
correct_year
<- (ib_DMUData[,"Year"]==2010)
active_dmus <-
(full_data*correct_year==1)
# OUTLIER BASED
FILTER THE BNETZA STANDARD
# PREPARATION
library(Benchmarking)
ib_MatrixDirection
<- as.matrix(ib_DMUData[active_dmus,c(ib_InputNames,ib_OutputNames)]) %*%
diag(ib_benchmarkDirection)
ib_inputMatrix
<- ib_DMUData[active_dmus,ib_InputNames,drop=FALSE]
ib_outputMatrix
<- ib_DMUData[active_dmus,ib_OutputNames,drop=FALSE]
ib_NumberActiveDMU
<- dim(ib_inputMatrix)[1]
# SUPER
EFFICIENCY OUTLIERS q_OUTLIER
ib_SuperResults<-sdea(ib_DMUData[active_dmus,ib_InputNames],
ib_DMUData[active_dmus,ib_OutputNames], ib_RTS,
ORIENTATION="in-out",DIRECT=ib_MatrixDirection)
q=as.matrix(quantile(1-ib_SuperResults$eff))
q_extreme <-
q[4,1]+1.5*(q[4,1]-q[2,1])
q_outlier
<-ifelse((1-ib_SuperResults$eff)>q_extreme,1,0)
# F TEST BASED OUTLIERS
F_outlier
B=dea(ib_inputMatrix,
ib_outputMatrix, ib_RTS,
ORIENTATION="in-out",DIRECT=ib_MatrixDirection)$eff
F_test =NULL
for ( i in
1:ib_NumberActiveDMU) {
A <-
dea(ib_inputMatrix[-i,,drop=FALSE],ib_outputMatrix[-i,,drop=FALSE],RTS =
ib_RTS,ORIENTATION="in-out",DIRECT=ib_MatrixDirection[-i,])$eff
SS1=t(A)%*%(A)
SS2=t(B[-i])%*%(B[-i])
C <-
pf(SS1/SS2, ib_NumberActiveDMU-1,ib_NumberActiveDMU-1)
F_test
<-rbind(F_test,C)
}
Prob_F_test <-
F_test[,1]
F_outlier <-
(Prob_F_test<0.05)
# THE FINAL SET OF CONDITONAL PEERS
ib_UserConditionalPeers <-
setdiff(ib_DMUData[active_dmus,"DMU"]*(1-q_outlier)*(1-F_outlier),0)
For mere om
R-koder, se www.r-project.org.
Variabeltransformation
Vtrans
Relevante variabel transformationer
kan defineres ved hjælp af R-koder i regnearket Vtrans. I et eksempel for en
skole anvendelse af Interactive Benchmarking er vist nedenfor. Vi definerer her
tre forskellige måder at præsentere eksamenskarakterer på.
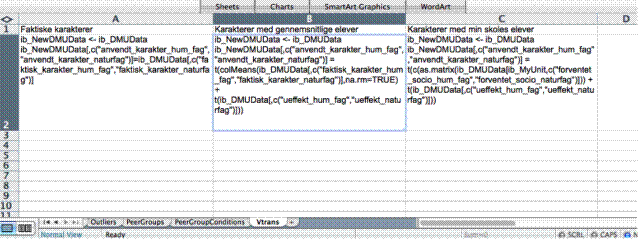
Hver kolonne
definerer en ny variabel-transformation. Navnet på transformationen, som det
vil se ud i fanebladet MinEnhed, er angivet i første række. R-koden der
definerer transformationen gives i anden række.
Ligesom i
Betingede Peer Grupper kan inputs til den R-baserede procedure være
ib_DMUData = en
matrix med data der er præcis ligesom data i DMUData-fanebladet fra xls-arket
ib_MyUnit = DMU
nummeret for Min Enhed
Outputtet skal være et nyt datasæt
ib_NewDMUData
der vil så tjene
som grundlag for de efterfølgende beregninger.
For mere om
R-koder, se www.r-project.org.
Historiefortælling
- Historiefortælling
Dynamiske data
Når der
foreligger data fra to eller flere perioder kan IB anvendes til dynamiske
analyser, dvs. til analyser af hvordan virksomhederne udvikler sig over tid.
Fanebladet
Dynamisk kommer automatisk til syne når de underliggende data indeholder flere
versioner af DMUData, nemlig det normale DMUData ark og en eller flere
alternative DMUData ark benævnt DMUData-1, DMUData-2, etc. Datasættet skal
desuden indeholde et ark kaldet Dynamic med information om hvilke perioder der
er data om, og hvordan disse skal benævnes i programmet.

Kolonnerne i
datasættene DMUData, DMUData-1, DMUData-2 osv, skal være de samme, men dette er
reelt ingen begrænsning, da de forskellige enheder kan have mangle data i
forskellige perioder.
Rækkerne i disse
datasæt behøver ikke indeholder helt de samme virksomheder.
IB vil automatisk
for hvert par af perioder bestemme, hvilke virksomheder der har de nødvendige
data, og det vil beregne de relevante indices baseret på disse
Den gruppe af
forbilleder, som er valgt og anvendt i Benchmark fanebladet, anvendes også i de
dynamiske beregninger
Format
Det er muligt
delvist at styre formatet for hvorledes tale vises i IB. Dette gøres ved at
indføre et faneblad i xls arket kaldet Format.
Man kan bruge et
Standard Format ved at indføre en Kolonne med overskriften Standard, eller man
kan bruge formater, der skifter mellem de forskellige faner Unit, KPI, Benchmark,
PeerUnits og Sector, som illustreret nedenfor:
Den definition af formatet kode følger beskrivelsen i
http://msdn.microsoft.com/en-us/library/dwhawy9k.aspx
F står for
eksempel for faste decimaltal og tallet givet efter F specificerer antallet af
decimaler efter kommaet. Brugen af decimal tegn, . eller ; bliver bestemt af
computeren hvis man arbejder med IBWin, og af serveren hvis man arbejder med
IBWeb. IBWeb bruger i øjeblikket USA-formatering, dvs. "." som
decimal separator og "," som tusindtalsseparator, hvis der bliver
anmodet om en sådan (N2 betyder for eksempel, at vi bruger to decimalcifre).
PARData
PARData arket indeholder den parametriske form der anvendes, når PAR er valgt som beregningsmetoden i Skala
menuen i Benchmark fanebladet.
Data er i PARData
arket gives i kolonner med overskrifter
- MODEL NUMEBER
- FORMULA
- GL
- GH
- LIMITITERATION
- Variabelforkortelser
MODEL NUMBER er
et nummer svarende til de modelnumre, der anvendes i arket ModelData.
FORMULA beskriver
Shepard’s input afstandsfunktion. Mulige input-output kombinationer er dem med
en værdi for Shepard input afstandsfunktionen større end eller lig med 1, og fronten
svarer til en Shepard afstand lig 1.
For at bestemme
punkter på den parametriske grænse, kan det godt være at Interaktiv
Benchmarking IB ® skal løse et eventuelt komplekst linjesøgningsproblem. For at
kunne gøre dette, bruger den en såkaldt bi-section metode. Forsøgsstartværdier
for denne procedure er givet vha. GL og GH, hvor GL er et forslag til en mulig
værdi og GH et forslag til en umulig værdi. Hvis dette ikke er tilfældet i
virkeligheden vil IB sænke GL og øge GH for at få en mulig startopstilling. Når
en mulig kombination af et punkt indenfor og et punkt udenfor produktionsfronten
er bestemt gennemfører IB et antal halveringer. Disse halveringer stopper, når
forskellen mellem de resulterende GL og GH værdier er mindre end 0,0001 – eller
når den øvre grænse LIMITITERATION nås.
Variabel
forkortelserne er de variable, der refereres til i FORMULA. I de pågældende
MODEL linjer er de tilhørende reelle input og output navne angivet svarende til
navnene i DMUData.

Kontrol af et nyt datasæt
Når et datasæt er
uploadet, kan det automatisk testes, om det opfylder en række af de vigtigste
krav. Hvis en af tabellerne for eksempel har to søjler med samme overskrift,
vil tabellerne ikke bestå integritetstesten, og der vil komme en advarsel frem
i testresultaterne.
